protectedAbstractCacheInvoker(CacheErrorHandler errorHandler){ Assert.notNull(errorHandler, "ErrorHandler must not be null"); this.errorHandler = errorHandler; }
@Override publicvoidafterPropertiesSet(){ Assert.state(getCacheOperationSource() != null, "The 'cacheOperationSources' property is required: " + "If there are no cacheable methods, then don't use a cache aspect."); Assert.state(getErrorHandler() != null, "The 'errorHandler' property is required"); }
@Override publicvoidafterSingletonsInstantiated(){ if (getCacheResolver() == null) { // Lazily initialize cache resolver via default cache manager... try { setCacheManager(this.beanFactory.getBean(CacheManager.class)); } catch (NoUniqueBeanDefinitionException ex) { thrownew IllegalStateException("No CacheResolver specified, and no unique bean of type " + "CacheManager found. Mark one as primary or declare a specific CacheManager to use."); } catch (NoSuchBeanDefinitionException ex) { thrownew IllegalStateException("No CacheResolver specified, and no bean of type CacheManager found. " + "Register a CacheManager bean or remove the @EnableCaching annotation from your configuration."); } } this.initialized = true; }
private Object execute(final CacheOperationInvoker invoker, Method method, CacheOperationContexts contexts){ // Special handling of synchronized invocation if (contexts.isSynchronized()) { CacheOperationContext context = contexts.get(CacheableOperation.class).iterator().next(); if (isConditionPassing(context, CacheOperationExpressionEvaluator.NO_RESULT)) { Object key = generateKey(context, CacheOperationExpressionEvaluator.NO_RESULT); Cache cache = context.getCaches().iterator().next(); try { return wrapCacheValue(method, cache.get(key, new Callable<Object>() { @Override public Object call()throws Exception { return unwrapReturnValue(invokeOperation(invoker)); } })); } catch (Cache.ValueRetrievalException ex) { // The invoker wraps any Throwable in a ThrowableWrapper instance so we // can just make sure that one bubbles up the stack. throw (CacheOperationInvoker.ThrowableWrapper) ex.getCause(); } } else { // No caching required, only call the underlying method return invokeOperation(invoker); } }
// Process any early evictions processCacheEvicts(contexts.get(CacheEvictOperation.class), true, CacheOperationExpressionEvaluator.NO_RESULT);
// Check if we have a cached item matching the conditions Cache.ValueWrapper cacheHit = findCachedItem(contexts.get(CacheableOperation.class));
// Collect puts from any @Cacheable miss, if no cached item is found List<CachePutRequest> cachePutRequests = new LinkedList<CachePutRequest>(); if (cacheHit == null) { collectPutRequests(contexts.get(CacheableOperation.class), CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests); }
Object cacheValue; Object returnValue;
if (cacheHit != null && cachePutRequests.isEmpty() && !hasCachePut(contexts)) { // If there are no put requests, just use the cache hit cacheValue = cacheHit.get(); returnValue = wrapCacheValue(method, cacheValue); } else { // Invoke the method if we don't have a cache hit returnValue = invokeOperation(invoker); cacheValue = unwrapReturnValue(returnValue); }
// Collect any explicit @CachePuts collectPutRequests(contexts.get(CachePutOperation.class), cacheValue, cachePutRequests);
// Process any collected put requests, either from @CachePut or a @Cacheable miss for (CachePutRequest cachePutRequest : cachePutRequests) { cachePutRequest.apply(cacheValue); }
// Process any late evictions processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue);
@Override publicvoidsetImportMetadata(AnnotationMetadata importMetadata){ this.enableCaching = AnnotationAttributes.fromMap( importMetadata.getAnnotationAttributes(EnableCaching.class.getName(), false)); if (this.enableCaching == null) { thrownew IllegalArgumentException( "@EnableCaching is not present on importing class " + importMetadata.getClassName()); } }
@Autowired(required = false) voidsetConfigurers(Collection<CachingConfigurer> configurers){ if (CollectionUtils.isEmpty(configurers)) { return; } if (configurers.size() > 1) { thrownew IllegalStateException(configurers.size() + " implementations of " + "CachingConfigurer were found when only 1 was expected. " + "Refactor the configuration such that CachingConfigurer is " + "implemented only once or not at all."); } CachingConfigurer configurer = configurers.iterator().next(); useCachingConfigurer(configurer); }
@Override publicvoidregisterBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry){ boolean candidateFound = false; Set<String> annTypes = importingClassMetadata.getAnnotationTypes(); for (String annType : annTypes) { AnnotationAttributes candidate = AnnotationConfigUtils.attributesFor(importingClassMetadata, annType); if (candidate == null) { continue; } Object mode = candidate.get("mode"); Object proxyTargetClass = candidate.get("proxyTargetClass"); if (mode != null && proxyTargetClass != null && AdviceMode.class == mode.getClass() && Boolean.class == proxyTargetClass.getClass()) { candidateFound = true; if (mode == AdviceMode.PROXY) { AopConfigUtils.registerAutoProxyCreatorIfNecessary(registry); if ((Boolean) proxyTargetClass) { AopConfigUtils.forceAutoProxyCreatorToUseClassProxying(registry); return; } } } } if (!candidateFound && logger.isWarnEnabled()) { String name = getClass().getSimpleName(); logger.warn(String.format("%s was imported but no annotations were found " + "having both 'mode' and 'proxyTargetClass' attributes of type " + "AdviceMode and boolean respectively. This means that auto proxy " + "creator registration and configuration may not have occurred as " + "intended, and components may not be proxied as expected. Check to " + "ensure that %s has been @Import'ed on the same class where these " + "annotations are declared; otherwise remove the import of %s " + "altogether.", name, name, name)); } }
privatestatic BeanDefinition registerOrEscalateApcAsRequired(Class<?> cls, BeanDefinitionRegistry registry, Object source){ Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
if (registry.containsBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME)) { BeanDefinition apcDefinition = registry.getBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME); if (!cls.getName().equals(apcDefinition.getBeanClassName())) { int currentPriority = findPriorityForClass(apcDefinition.getBeanClassName()); int requiredPriority = findPriorityForClass(cls); if (currentPriority < requiredPriority) { apcDefinition.setBeanClassName(cls.getName()); } } returnnull; }
privatestaticfinal List<Class<?>> APC_PRIORITY_LIST = new ArrayList<Class<?>>(3);
static { // Set up the escalation list... APC_PRIORITY_LIST.add(InfrastructureAdvisorAutoProxyCreator.class); APC_PRIORITY_LIST.add(AspectJAwareAdvisorAutoProxyCreator.class); APC_PRIORITY_LIST.add(AnnotationAwareAspectJAutoProxyCreator.class); }
private Object execute(final CacheOperationInvoker invoker, Method method, CacheOperationContexts contexts){ // Special handling of synchronized invocation if (contexts.isSynchronized()) { CacheOperationContext context = contexts.get(CacheableOperation.class).iterator().next(); if (isConditionPassing(context, CacheOperationExpressionEvaluator.NO_RESULT)) { Object key = generateKey(context, CacheOperationExpressionEvaluator.NO_RESULT); Cache cache = context.getCaches().iterator().next(); try { return wrapCacheValue(method, cache.get(key, new Callable<Object>() { @Override public Object call()throws Exception { return unwrapReturnValue(invokeOperation(invoker)); } })); } catch (Cache.ValueRetrievalException ex) { // The invoker wraps any Throwable in a ThrowableWrapper instance so we // can just make sure that one bubbles up the stack. throw (CacheOperationInvoker.ThrowableWrapper) ex.getCause(); } } else { // No caching required, only call the underlying method return invokeOperation(invoker); } }
// Process any early evictions processCacheEvicts(contexts.get(CacheEvictOperation.class), true, CacheOperationExpressionEvaluator.NO_RESULT);
// Check if we have a cached item matching the conditions Cache.ValueWrapper cacheHit = findCachedItem(contexts.get(CacheableOperation.class));
// Collect puts from any @Cacheable miss, if no cached item is found List<CachePutRequest> cachePutRequests = new LinkedList<CachePutRequest>(); if (cacheHit == null) { collectPutRequests(contexts.get(CacheableOperation.class), CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests); }
Object cacheValue; Object returnValue;
if (cacheHit != null && cachePutRequests.isEmpty() && !hasCachePut(contexts)) { // If there are no put requests, just use the cache hit cacheValue = cacheHit.get(); returnValue = wrapCacheValue(method, cacheValue); } else { // Invoke the method if we don't have a cache hit returnValue = invokeOperation(invoker); cacheValue = unwrapReturnValue(returnValue); }
// Collect any explicit @CachePuts collectPutRequests(contexts.get(CachePutOperation.class), cacheValue, cachePutRequests);
// Process any collected put requests, either from @CachePut or a @Cacheable miss for (CachePutRequest cachePutRequest : cachePutRequests) { cachePutRequest.apply(cacheValue); }
// Process any late evictions processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue);
Spring 框架本身利用了这些注释,但是它们也可以在任何基于 Spring 的 Java 项目中使用,以声明 null 安全的 API 和可选的 null 安全的字段。尚不支持泛型类型参数,varargs 和数组元素的可空性,但应在即将发布的版本中使用它们,有关最新信息,请参见 SPR-15942。可空性声明预计将在 Spring Framework 版本之间进行微调,包括次要版本。在方法主体内部使用的类型的可空性超出了此功能的范围。
其他常见的库(如 Reactor 和 Spring Data)提供了使用类似可空性设置的空安全 API,从而为 Spring 应用程序开发人员提供了一致的总体体验。
用例
除了为 Spring Framework API 可空性提供显式声明外,IDE(例如 IDEA 或 Eclipse)还可以使用这些批注提供与空安全有关的有用警告,以避免在运行时出现 NullPointerException。
由于 Kotlin 原生支持 null 安全,因此它们还用于在 Kotlin 项目中使 Spring API 为 null 安全。 Kotlin 支持文档中提供了更多详细信息。
JSR-305 元注释
Spring 注释使用 JSR 305 注释(静止但广泛使用的 JSR)进行元注释。 JSR-305 元注释使工具供应商(如 IDEA 或 Kotlin)以通用方式提供了空安全支持,而无需对 Spring 注释进行硬编码支持。
既不需要也不建议向项目类路径添加 JSR-305 依赖项以利用 Spring 空安全 API。只有诸如在其代码库中使用空安全注释的基于 Spring 的库之类的项目,才应添加 com.google.code.findbugs:jsr305:3.0.2(具有 compileOnly Gradle 配置或 Maven provided 的范围),以避免编译警告。
切入点匹配的连接点的概念是 AOP 的关键,它与仅提供拦截功能的旧技术有所不同。切入点使 advice 的目标独立于面向对象的层次结构。例如,您可以将提供声明性事务管理的 around advice 应用于跨越多个对象(例如服务层中的所有业务操作)的一组方法。
Spring AOP 能力和目标
Spring AOP 是用纯 Java 实现的。不需要特殊的编译过程。 Spring AOP 不需要控制类加载器的层次结构,因此适合在 Servlet 容器或应用程序服务器中使用。
Spring AOP 当前仅支持方法执行连接点( advice 在 Spring Bean 执行方法上)。尽管可以在不破坏核心 Spring AOP API 的情况下添加对字段拦截的支持,但并未实现字段拦截。如果需要 advice 字段访问和更新连接点,请考虑使用诸如 AspectJ 之类的语言。
Spring AOP 的 AOP 方法不同于大多数其他 AOP 框架。目的不是提供最完整的 AOP 实现(尽管 Spring AOP 相当强大)。相反,其目的是在 AOP 实现和 Spring IoC 之间提供紧密的集成,以帮助解决企业应用程序中的常见问题。
因此,例如,通常将 Spring Framework 的 AOP 功能与 Spring IoC 容器结合使用。通过使用常规 bean 定义语法来配置切面(尽管这允许强大的“自动代理”功能)。这是与其他 AOP 实现的关键区别。使用 Spring AOP 不能轻松或高效地完成某些事情,例如 advice 非常细粒度的对象(通常是域对象)。在这种情况下,AspectJ 是最佳选择。但是,我们的经验是,Spring AOP 为 AOP 可以解决的企业 Java 应用程序中的大多数问题提供了出色的解决方案。
Spring AOP 从未努力与 AspectJ 竞争以提供全面的 AOP 解决方案。我们认为,基于代理的框架(如 Spring AOP)和成熟的框架(如 AspectJ)都是有价值的,它们是互补的,而不是竞争。 Spring 无缝地将 Spring AOP 和 IoC 与 AspectJ 集成在一起,以在基于 Spring 的一致应用程序架构中支持 AOP 的所有使用。这种集成不会影响 Spring AOP API 或 AOP Alliance API。 Spring AOP 仍然向后兼容。请参阅下一章,以讨论 Spring AOP API。
Spring 框架的中心宗旨之一是非侵入性。这是一个想法,您不应被迫将特定于框架的类和接口引入业务或域模型。但是,在某些地方,Spring Framework 确实为您提供了将特定于 Spring Framework 的依赖项引入代码库的选项。提供此类选项的理由是,在某些情况下,以这种方式阅读或编码某些特定功能可能会变得更加容易。但是,Spring 框架(几乎)总是为您提供选择:您可以自由地就哪个选项最适合您的特定用例或场景做出明智的决定。
与本章相关的一种选择是选择哪种 AOP 框架(以及哪种 AOP 样式)。您可以选择 AspectJ 和/或 Spring AOP。您也可以选择 @AspectJ 注释样式方法或 Spring XML 配置样式方法。本章选择首先介绍 @AspectJ 风格的方法这一事实不应被视为表明 Spring 团队比 Spring XML 配置风格更喜欢 @AspectJ 注释风格的方法。
您可以将切面类注册为 Spring XML 配置中的常规 bean,也可以通过类路径扫描自动检测它们——与其他任何 Spring 管理的 bean 一样。 但是,请注意,@Aspect 注释不足以在类路径中进行自动检测。为此,您需要添加一个单独的 @Component 批注(或者,或者,按照 Spring 的组件扫描程序的规则,有条件的自定义构造型批注)。
向其他切面提供 advice ?
在 Spring AOP 中,切面本身不能成为其他切面的 advice 目标。 类上的 @Aspect 注释将其标记为一个切面,因此将其从自动代理中排除。
声明切入点
切入点确定了感兴趣的连接点,从而使我们能够控制何时执行 advice 。 Spring AOP 仅支持 Spring Bean 的方法执行连接点,因此您可以将切入点视为与 Spring Bean 上的方法执行匹配。 切入点声明由两部分组成:一个包含名称和任何参数的签名,以及一个切入点表达式,该切入点表达式精确确定我们感兴趣的方法执行。在 AOP 的@AspectJ 批注样式中,常规方法定义提供了切入点签名。 ,并使用 @Pointcut 批注指示切入点表达式(用作切入点签名的方法必须具有 void 返回类型)。
一个示例可能有助于使切入点签名和切入点表达式之间的区别变得清晰。 下面的示例定义一个名为 anyOldTransfer 的切入点,该切入点与任何名为 transfer 的方法的执行相匹配:
1 2
@Pointcut("execution(* transfer(..))") // the pointcut expression privatevoidanyOldTransfer(){} // the pointcut signature
Spring AOP 支持的切入点指示符集合可能会在将来的版本中扩展,以支持更多的 AspectJ 切入点指示符。
由于 Spring AOP 仅将匹配限制为仅方法执行连接点,因此前面对切入点指示符的讨论所给出的定义比在 AspectJ 编程指南中所能找到的要窄。此外,AspectJ 本身具有基于类型的语义,并且在执行连接点处,此对象和目标都引用同一个对象:执行该方法的对象。 Spring AOP 是基于代理的系统,可区分代理对象本身(绑定到此对象)和代理后面的目标对象(绑定到目标)。
由于 Spring 的 AOP 框架基于代理的性质,因此根据定义,不会拦截目标对象内的调用。对于 JDK 代理,只能拦截代理上的公共接口方法调用。使用 CGLIB,将拦截代理上的公共方法和受保护的方法调用(必要时甚至包可见的方法)。但是,通常应通过公共签名设计通过代理进行的常见交互。
/** * A join point is in the web layer if the method is defined * in a type in the com.xyz.someapp.web package or any sub-package * under that. */ @Pointcut("within(com.xyz.someapp.web..*)") publicvoidinWebLayer(){}
/** * A join point is in the service layer if the method is defined * in a type in the com.xyz.someapp.service package or any sub-package * under that. */ @Pointcut("within(com.xyz.someapp.service..*)") publicvoidinServiceLayer(){}
/** * A join point is in the data access layer if the method is defined * in a type in the com.xyz.someapp.dao package or any sub-package * under that. */ @Pointcut("within(com.xyz.someapp.dao..*)") publicvoidinDataAccessLayer(){}
/** * A business service is the execution of any method defined on a service * interface. This definition assumes that interfaces are placed in the * "service" package, and that implementation types are in sub-packages. * * If you group service interfaces by functional area (for example, * in packages com.xyz.someapp.abc.service and com.xyz.someapp.def.service) then * the pointcut expression "execution(* com.xyz.someapp..service.*.*(..))" * could be used instead. * * Alternatively, you can write the expression using the 'bean' * PCD, like so "bean(*Service)". (This assumes that you have * named your Spring service beans in a consistent fashion.) */ @Pointcut("execution(* com.xyz.someapp..service.*.*(..))") publicvoidbusinessService(){}
/** * A data access operation is the execution of any method defined on a * dao interface. This definition assumes that interfaces are placed in the * "dao" package, and that implementation types are in sub-packages. */ @Pointcut("execution(* com.xyz.someapp.dao.*.*(..))") publicvoiddataAccessOperation(){}
当在不同切面定义的两条 advice 都需要在同一连接点上运行时,除非另行指定,否则执行顺序是不确定的。您可以通过指定优先级来控制执行顺序。通过在切面类中实现 org.springframework.core.Ordered 接口或使用 Order 批注对其进行注释,可以通过常规的 Spring 方法来完成。给定两个切面,从 Ordered.getValue()(或注释值)返回较低值的切面具有较高的优先级。
如果您选择使用 Spring AOP,则可以选择 @AspectJ 或 XML 样式。有各种折衷考虑。
XML 样式可能是现有 Spring 用户最熟悉的,并且得到了真正的 POJO 的支持。当使用 AOP 作为配置企业服务的工具时,XML 是一个不错的选择(一个很好的测试是您是否将切入点表达式视为您可能希望独立更改的配置的一部分)。使用 XML 样式,可以说从您的配置中可以更清楚地了解系统中存在哪些切面。
XML 样式有两个缺点。首先,它没有完全将要解决的需求的实现封装在一个地方。 DRY 原则说,系统中的任何知识都应该有一个单一,明确,权威的表示形式。使用 XML 样式时,关于如何实现需求的知识会在配置文件中的后备 bean 类的声明和 XML 中分散。当您使用@AspectJ 样式时,此信息将封装在一个模块中:切面。其次,与@AspectJ 样式相比,XML 样式在表达能力上有更多限制:仅支持“单例”切面实例化模型,并且无法组合以 XML 声明的命名切入点。例如,使用@AspectJ 样式,您可以编写如下内容:
好吧,那么该怎么办? 最佳方法(在这里宽松地使用术语“最佳”)是重构代码,以免发生自调用。这确实需要您做一些工作,但这是最好的,侵入性最小的方法。下一种方法绝对可怕,我们正要指出这一点,恰恰是因为它是如此可怕。您可以(对我们来说是痛苦的)完全将类中的逻辑与 Spring AOP 绑定在一起,如以下示例所示:
1 2 3 4 5 6 7 8 9 10 11
publicclassSimplePojoimplementsPojo{
publicvoidfoo(){ // this works, but... gah! ((Pojo) AopContext.currentProxy()).bar(); }
publicvoidbar(){ // some logic... } }
这将您的代码完全耦合到 Spring AOP,并且使类本身意识到在 AOP 上下文中使用它的事实,而 AOP 上下文却是这样。创建代理时,还需要一些其他配置,如以下示例所示:
// create a factory that can generate a proxy for the given target object AspectJProxyFactory factory = new AspectJProxyFactory(targetObject);
// add an aspect, the class must be an @AspectJ aspect // you can call this as many times as you need with different aspects factory.addAspect(SecurityManager.class);
// you can also add existing aspect instances, the type of the object supplied must be an @AspectJ aspect factory.addAspect(usageTracker);
// now get the proxy object... MyInterfaceType proxy = factory.getProxy();
最后,您可以使用 dependencyCheck 属性(例如,@Configurable(autowire=Autowire.BY_NAME,dependencyCheck=true))为新创建和配置的对象中的对象引用启用 Spring 依赖检查。如果此属性设置为 true,则 Spring 在配置后验证是否已设置所有属性(不是基本类型或集合)。
请注意,单独使用注释不会执行任何操作。spring-aspects.jar 中的 AnnotationBeanConfigurerAspect 会对注释的存在起作用。从本质上讲,切面说:“在从带有 @Configurable 注释的类型的新对象的初始化返回之后,使用 Spring 根据注释的属性配置新创建的对象”。在这种情况下,“初始化”是指新实例化的对象(例如,用 new 运算符实例化的对象)以及正在进行反序列化(例如,通过 readResolve() 的可序列化的对象)。
考虑一个典型的 Spring Web 应用程序配置,该配置具有一个共享的父应用程序上下文,该上下文定义了通用的业务服务,支持那些服务所需的一切,以及每个 Servlet 的一个子应用程序上下文(其中包含该 Servlet 的特定定义)。所有这些上下文共存于同一类加载器层次结构中,因此 AnnotationBeanConfigurerAspect 只能保存对其中一个的引用。在这种情况下,我们建议在共享(父)应用程序上下文中定义@EnableSpringConfigured bean。这定义了您可能想注入域对象的服务。结果是,您无法使用@Configurable 机制来配置域对象,该域对象引用的是在子(特定于 servlet 的)上下文中定义的 Bean 的引用(无论如何,这可能不是您想要做的)。
在同一容器中部署多个 Web 应用程序时,请确保每个 Web 应用程序通过使用其自己的类加载器(例如,将 spring-aspects.jar 放置在 'WEB-INF/lib' 中)将其类型加载到 spring-aspects.jar 中。如果将 spring-aspects.jar 仅添加到容器级的类路径中(并因此由共享的父类加载器加载),则所有 Web 应用程序都共享相同的切面实例(可能不是您想要的)。
AspectJ 的其他 Spring 切面
除了 @Configurable 切面之外,spring-aspects.jar 还包含一个 AspectJ 切面,您可以使用该切面来驱动 Spring 的事务管理,以使用 @Transactional 批注来批注类型和方法。这主要适用于希望在 Spring 容器之外使用 Spring Framework 的事务支持的用户。
// the creation of a new bean (any object in the domain model) protected pointcut beanCreation(Object beanInstance) : initialization(new(..)) && SystemArchitecture.inDomainModel() && this(beanInstance); }
使用 Spring IoC 配置 AspectJ Aspects
当您将 AspectJ 切面与 Spring 应用程序一起使用时,既自然又希望能够使用 Spring 配置这些切面。 AspectJ 运行时本身负责切面的创建,并且通过 Spring 配置 AspectJ 创建的切面的方法取决于切面所使用的 AspectJ 实例化模型(per-xxx 子句)。
强烈推荐 Ramnivas Laddad 撰写的《AspectJ in Action》第二版(Manning,2009 年)。本书的重点是 AspectJ,但是(在一定程度上)探讨了许多通用的 AOP 主题。
]]> 技术 阅读 Spring Java <![CDATA[Spring进阶 - spring 表达式语言(SpEL)]]>https://HaleLu.github.io/2020/06/spring-5/书接上文
接下来到 Spring framework core 的第四大块 —— spring 表达式语言(SpEL)
spring 表达式语言(SpEL)
Spring 表达式语言(简称“SpEL”)是一种功能强大的表达式语言,支持在运行时查询和操作对象图。语言语法与 Unified EL 相似,但提供了其他功能,最著名的是方法调用和基本的字符串模板功能。
尽管还有其他几种 Java 表达式语言可用-OGNL,MVEL 和 JBoss EL,仅举几例-Spring 表达式语言的创建是为了向 Spring 社区提供一种受良好支持的表达式语言,该语言可用于以下版本中的所有产品春季投资组合。它的语言功能受 Spring 产品组合中项目的要求驱动,包括 Spring Tools for Eclipse 中代码完成支持的工具要求。也就是说,SpEL 基于与技术无关的 API,如果需要,可以将其他表达语言实现集成在一起。
虽然 SpEL 是 Spring 产品组合中表达评估的基础,但它并不直接与 Spring 绑定,可以独立使用。为了自成一体,本章中的许多示例都将 SpEL 用作独立的表达语言。这需要创建一些自举基础结构类,例如解析器。 Spring 的大多数用户不需要处理这种基础结构,而只能编写表达式字符串进行评估。这种典型用法的一个示例是将 SpEL 集成到创建 XML 或基于注释的 Bean 定义中,如 Expression 支持中定义的 Bean 定义所示。
本章介绍了表达语言,其 API 和语言语法的功能。在许多地方,Inventor 和 Society 类都用作表达评估的目标对象。这些类声明和用于填充它们的数据在本章末尾列出。
默认情况下,SpEL 使用 Spring 核心中可用的转换服务(org.springframework.core.convert.ConversionService)。此转换服务附带许多内置转换器,用于常见转换,但也可以完全扩展,以便您可以在类型之间添加自定义转换。此外,它是泛型感知的。这意味着,当您在表达式中使用泛型类型时,SpEL 会尝试进行转换以维护遇到的任何对象的类型正确性。
实际上这是什么意思?假设使用 setValue() 进行赋值来设置 List 属性。该属性的类型实际上是 List<Boolean>。 SpEL 认识到列表中的元素在放入列表之前需要转换为布尔值。以下示例显示了如何执行此操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSimple{ public List<Boolean> booleanList = new ArrayList<Boolean>(); }
Simple simple = new Simple(); simple.booleanList.add(true);
// "false" is passed in here as a String. SpEL and the conversion service // will recognize that it needs to be a Boolean and convert it accordingly. parser.parseExpression("booleanList[0]").setValue(context, simple, "false");
// b is false Boolean b = simple.booleanList.get(0);
// Turn on: // - auto null reference initialization // - auto collection growing SpelParserConfiguration config = new SpelParserConfiguration(true,true);
ExpressionParser parser = new SpelExpressionParser(config);
// evaluates to a Java map containing the two entries Map inventorInfo = (Map) parser.parseExpression("{name:'Nikola',dob:'10-July-1856'}").getValue(context);
// evaluates to false boolean falseValue = parser.parseExpression("true and false").getValue(Boolean.class);
// evaluates to true String expression = "isMember('Nikola Tesla') and isMember('Mihajlo Pupin')"; boolean trueValue = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
// -- OR --
// evaluates to true boolean trueValue = parser.parseExpression("true or false").getValue(Boolean.class);
// evaluates to true String expression = "isMember('Nikola Tesla') or isMember('Albert Einstein')"; boolean trueValue = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
// -- NOT --
// evaluates to false boolean falseValue = parser.parseExpression("!true").getValue(Boolean.class);
// -- AND and NOT -- String expression = "isMember('Nikola Tesla') and !isMember('Mihajlo Pupin')"; boolean falseValue = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
您可以使用 new 运算符来调用构造函数。 除基本类型(int,float 等)和 String 以外的所有其他类都应使用完全限定的类名。 下面的示例演示如何使用 new 运算符调用构造函数:
1 2 3 4 5 6 7 8
Inventor einstein = p.parseExpression( "new org.spring.samples.spel.inventor.Inventor('Albert Einstein', 'German')") .getValue(Inventor.class);
//create new inventor instance within add method of List p.parseExpression( "Members.add(new org.spring.samples.spel.inventor.Inventor( 'Albert Einstein', 'German'))").getValue(societyContext);
// create an array of integers List<Integer> primes = new ArrayList<Integer>(); primes.addAll(Arrays.asList(2,3,5,7,11,13,17));
// create parser and set variable 'primes' as the array of integers ExpressionParser parser = new SpelExpressionParser(); EvaluationContext context = SimpleEvaluationContext.forReadOnlyDataAccess(); context.setVariable("primes", primes);
// all prime numbers > 10 from the list (using selection ?{...}) // evaluates to [11, 13, 17] List<Integer> primesGreaterThanTen = (List<Integer>) parser.parseExpression( "#primes.?[#this>10]").getValue(context);
ExpressionParser parser = new SpelExpressionParser(); StandardEvaluationContext context = new StandardEvaluationContext(); context.setBeanResolver(new MyBeanResolver());
// This will end up calling resolve(context,"something") on MyBeanResolver during evaluation Object bean = parser.parseExpression("@something").getValue(context);
要访问工厂 bean 本身,您应该在 bean 名称前加上&符号。 以下示例显示了如何执行此操作:
1 2 3 4 5 6
ExpressionParser parser = new SpelExpressionParser(); StandardEvaluationContext context = new StandardEvaluationContext(); context.setBeanResolver(new MyBeanResolver());
// This will end up calling resolve(context,"&foo") on MyBeanResolver during evaluation Object bean = parser.parseExpression("&foo").getValue(context);
expression = "isMember(#queryName)? #queryName + ' is a member of the ' " + "+ Name + ' Society' : #queryName + ' is not a member of the ' + Name + ' Society'";
String queryResultString = parser.parseExpression(expression) .getValue(societyContext, String.class); // queryResultString = "Nikola Tesla is a member of the IEEE Society"
有关三元运算符的更短语法,请参阅关于 Elvis 运算符的下一部分。
Elvis 运算符
Elvis 运算符是三元运算符语法的简化,并且在 Groovy 语言中使用。 使用三元运算符语法,通常必须将变量重复两次,如以下示例所示:
1 2
String name = "Elvis Presley"; String displayName = (name != null ? name : "Unknown");
相反,您可以使用 Elvis 运算符(其命名类似于 Elvis 的发型)。 以下示例显示了如何使用 Elvis 运算符:
1 2 3 4
ExpressionParser parser = new SpelExpressionParser();
String name = parser.parseExpression("name?:'Unknown'").getValue(new Inventor(), String.class); System.out.println(name); // 'Unknown'
以下显示了一个更复杂的示例:
1 2 3 4 5 6 7 8 9 10
ExpressionParser parser = new SpelExpressionParser(); EvaluationContext context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
Inventor tesla = new Inventor("Nikola Tesla", "Serbian"); String name = parser.parseExpression("Name?:'Elvis Presley'").getValue(context, tesla, String.class); System.out.println(name); // Nikola Tesla
tesla.setName(null); name = parser.parseExpression("Name?:'Elvis Presley'").getValue(context, tesla, String.class); System.out.println(name); // Elvis Presley
您可以使用 Elvis 运算符在表达式中应用默认值。 以下示例显示了如何在 @Value 表达式中使用 Elvis 运算符:
ExpressionParser parser = new SpelExpressionParser(); EvaluationContext context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
Inventor tesla = new Inventor("Nikola Tesla", "Serbian"); tesla.setPlaceOfBirth(new PlaceOfBirth("Smiljan"));
String city = parser.parseExpression("PlaceOfBirth?.City").getValue(context, tesla, String.class); System.out.println(city); // Smiljan
tesla.setPlaceOfBirth(null); city = parser.parseExpression("PlaceOfBirth?.City").getValue(context, tesla, String.class); System.out.println(city); // null - does not throw NullPointerException!!!
集合选择
选择是一种强大的表达语言功能,可让您通过从源集合中进行选择来将其转换为另一个集合。
选择使用 .?[selectionExpression] 的语法。 它过滤集合并返回一个包含原始元素子集的新集合。例如,通过选择,我们可以轻松地获得 Serbian inventors 的列表,如以下示例所示:
1 2
List<Inventor> list = (List<Inventor>) parser.parseExpression( "Members.?[Nationality == 'Serbian']").getValue(societyContext);
publicCustomerValidator(Validator addressValidator){ if (addressValidator == null) { thrownew IllegalArgumentException("The supplied [Validator] is " + "required and must not be null."); } if (!addressValidator.supports(Address.class)) { thrownew IllegalArgumentException("The supplied [Validator] must " + "support the validation of [Address] instances."); } this.addressValidator = addressValidator; }
/** * This Validator validates Customer instances, and any subclasses of Customer too */ publicbooleansupports(Class clazz){ return Customer.class.isAssignableFrom(clazz); }
BeanWrapper company = new BeanWrapperImpl(new Company()); // setting the company name.. company.setPropertyValue("name", "Some Company Inc."); // ... can also be done like this: PropertyValue value = new PropertyValue("name", "Some Company Inc."); company.setPropertyValue(value);
// ok, let's create the director and tie it to the company: BeanWrapper jim = new BeanWrapperImpl(new Employee()); jim.setPropertyValue("name", "Jim Stravinsky"); company.setPropertyValue("managingDirector", jim.getWrappedInstance());
// retrieving the salary of the managingDirector through the company Float salary = (Float) company.getPropertyValue("managingDirector.salary");
内置的 PropertyEditor 实现
pring 使用 PropertyEditor 的概念来实现对象和字符串之间的转换。以不同于对象本身的方式表示属性可能很方便。例如,日期可以用人类可读的方式表示(如字符串:”2007-14-09”),而我们仍然可以将人类可读的形式转换回原始日期(或者更好的是,转换任何日期以人类可读的形式输入到 Date 对象)。通过注册类型为 java.beans.PropertyEditor 的自定义编辑器,可以实现此行为。在 BeanWrapper 上或在特定的 IoC 容器中注册自定义编辑器(如上一章所述),使它具有如何将属性转换为所需类型的知识。有关 PropertyEditor 的更多信息,请参见 Oracle 的 java.beans 包的 javadoc。
在 Spring 中使用属性编辑的两个示例:
通过使用 PropertyEditor 实现在 bean 上设置属性。当使用 String 作为在 XML 文件中声明的某个 bean 的属性的值时,Spring(如果相应属性的设置器具有 Class 参数)将使用 ClassEditor 尝试将参数解析为 Class 对象。
要创建自己的转换器,请实现 Converter 接口并将 S 设置为要转换的类型,并将 T 设置为要转换的类型。如果还需要注册一个委托数组或集合转换器(默认情况下 DefaultConversionService 会这样做),则也可以透明地应用此类转换器,如果需要将 S 的集合或数组转换为 T 的数组或集合。
@Bean public FormattingConversionService conversionService(){
// Use the DefaultFormattingConversionService but do not register defaults DefaultFormattingConversionService conversionService = new DefaultFormattingConversionService(false);
// Ensure @NumberFormat is still supported conversionService.addFormatterForFieldAnnotation(new NumberFormatAnnotationFormatterFactory());
// Register JSR-310 date conversion with a specific global format DateTimeFormatterRegistrar registrar = new DateTimeFormatterRegistrar(); registrar.setDateFormatter(DateTimeFormatter.ofPattern("yyyyMMdd")); registrar.registerFormatters(conversionService);
// Register date conversion with a specific global format DateFormatterRegistrar registrar = new DateFormatterRegistrar(); registrar.setFormatter(new DateFormatter("yyyyMMdd")); registrar.registerFormatters(conversionService);
return conversionService; } }
如果您喜欢基于 XML 的配置,则可以使用 FormattingConversionServiceFactoryBean。 以下示例显示了如何执行此操作(这次使用 Joda Time):
然后,Bean 验证验证器根据声明的约束来验证此类的实例。 有关该 API 的一般信息,请参见 Bean 验证。 有关特定限制,请参见 Hibernate Validator 文档。 要学习如何将 bean 验证提供程序设置为 Spring bean,请继续阅读。
配置 Bean 验证提供程序
Spring 提供了对 Bean 验证 API 的全面支持,包括将 Bean 验证提供程序作为 Spring Bean 进行引导。 这使您可以在应用程序中需要验证的任何地方注入 javax.validation.ValidatorFactory 或 javax.validation.Validator。
您可以使用 LocalValidatorFactoryBean 将默认的 Validator 配置为 Spring Bean,如以下示例所示:
当需要资源时,Spring 本身广泛使用 Resource 抽象作为许多方法签名中的参数类型。一些 Spring API 中的其他方法(例如,各种 ApplicationContext 实现的构造函数)采用 String 形式,该字符串以未经修饰或简单的形式用于创建适合该上下文实现的 Resource,或者通过 String 路径上的特殊前缀,让调用者指定必须创建并使用特定的资源实现。
尽管 Spring 经常使用 Resource 接口,但实际上,在您自己的代码中单独用作通用实用工具类来访问资源也非常有用,即使您的代码不了解也不关心 Spring 的其他任何部分。虽然这将您的代码耦合到 Spring,但实际上仅将其耦合到这套实用程序类,它们充当 URL 的更强大替代,并且可以被视为等同于您将用于此目的的任何其他库。
如果指定的路径是类路径位置,则解析器必须通过调用 Classloader.getResource()获得最后的非通配符路径段 URL。由于这只是路径的一个节点(而不是末尾的文件),因此实际上(在 ClassLoader javadoc 中)未定义确切返回的是哪种 URL。实际上,它始终是代表目录的 java.io.File(类路径资源在其中解析到文件系统位置)或某种 jar URL(类路径资源在 jar 上解析)。尽管如此,此操作仍存在可移植性问题。
如果为最后一个非通配符段获取了 jar URL,则解析程序必须能够从中获取 java.net.JarURLConnection 或手动解析 jar URL,以便能够遍历 jar 的内容并解析通配符。这在大多数环境中确实有效,但在其他环境中则无效,因此我们强烈建议您在依赖特定环境之前,对来自 jars 的资源的通配符解析进行彻底测试。
classpath*: 前缀
在构造基于 XML 的应用程序上下文时,位置字符串可以使用特殊的 classpath*: 前缀,如以下示例所示:
1 2
ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath*:conf/appContext.xml");
请注意,当 classpath*: 与 Ant 样式的模式结合使用时,除非模式文件实际驻留在文件系统中,否则在模式启动之前,它只能与至少一个根目录可靠地一起工作。这意味着诸如 classpath*:*.xml 之类的模式可能不会从 jar 文件的根目录检索文件,而只会从扩展目录的根目录检索文件。
Spring 检索类路径条目的能力源自 JDK 的 ClassLoader.getResources() 方法,该方法仅返回文件系统中的空字符串位置(指示可能要搜索的根目录)。 Spring 还会评估 jar 文件中的 URLClassLoader 运行时配置和 java.class.path 清单,但这不能保证会导致可移植行为。
// actual context type doesn't matter, the Resource will always be UrlResource ctx.getResource("file:///some/resource/path/myTemplate.txt");
1 2 3
// force this FileSystemXmlApplicationContext to load its definition via a UrlResource ApplicationContext ctx = new FileSystemXmlApplicationContext("file:///conf/context.xml");
]]> 技术 阅读 Spring Java <![CDATA[Spring进阶 - IoC容器(2)]]>https://HaleLu.github.io/2020/04/spring-2/书接上文
<beanid="lifecycleProcessor"class="org.springframework.context.support.DefaultLifecycleProcessor"> <!-- timeout value in milliseconds --> <propertyname="timeoutPerShutdownPhase"value="10000"/> </bean>
在非 Web 应用程序中优雅地关闭 Spring IoC 容器
Spring 的基于 Web 的 ApplicationContext 实现已经可以在相关 Web 应用程序关闭时正常关闭 Spring IoC 容器。本节仅适用于非 Web 应用程序。
如果在非 Web 应用程序环境中使用 Spring 的 IoC 容器(例如,在客户机桌面环境中),请使用 JVM 注册 shutdown hook。这样做可确保正常关闭并在单例 bean 上调用相关的 destroy 方法,以便释放所有资源。我们依然必须正确配置和实现这些 destroy 回调。
<beanid="inheritsWithDifferentClass" class="org.springframework.beans.DerivedTestBean" parent="inheritedTestBean"init-method="initialize"> <propertyname="name"value="override"/> <!-- the age property value of 1 will be inherited from parent --> </bean>
<beanid="inheritsWithClass"class="org.springframework.beans.DerivedTestBean" parent="inheritedTestBeanWithoutClass"init-method="initialize"> <propertyname="name"value="override"/> <!-- age will inherit the value of 1 from the parent bean definition--> </bean>
// simply return the instantiated bean as-is public Object postProcessBeforeInitialization(Object bean, String beanName){ return bean; // we could potentially return any object reference here... }
// simply return the instantiated bean as-is public Object postProcessBeforeInitialization(Object bean, String beanName){ return bean; // we could potentially return any object reference here... }
<lang:groovyid="messenger" script-source="classpath:org/springframework/scripting/groovy/Messenger.groovy"> <lang:propertyname="message"value="Fiona Apple Is Just So Dreamy."/> </lang:groovy>
<!-- when the above bean (messenger) is instantiated, this custom BeanPostProcessor implementation will output the fact to the system console --> <beanclass="scripting.InstantiationTracingBeanPostProcessor"/>
将回调接口或注释与自定义 BeanPostProcessor 实现结合使用是扩展 Spring IoC 容器的常用方法。一个例子是 Spring 的 RequiredAnnotationBeanPostProcessor —— 一个 Spring 提供的 BeanPostProcessor 实现,它保证用 @Required(或者其他自定义的)注释标记的 bean 上的属性一定有值注入。
// Inject all Store beans as long as they have an <Integer> generic // Store<String> beans will not appear in this list @Autowired private List<Store<Integer>> s;
使用 CustomAutowireConfigurer
CustomAutowireConfigurer 是一个 BeanFactoryPostProcessor,它允许注册自己的自定义限定符注释类型,即使它们没有使用 Spring 的 @Qualifier 注释进行注释。 以下示例显示如何使用 CustomAutowireConfigurer:
有关特定于 Web 的范围的详细信息,例如 Spring 上下文中的“request”或“session”,请参见 Request,Session,Application 和 WebSocket Scope。与这些作用域的预构建批注一样,您也可以使用 Spring 的元注释方法来组成自己的作用域注释:例如,用@Scope(“prototype”),进行元注释的自定义注释,也可能会声明自定义作用域代理模式。
在@Qualifier 注释中讨论与预选赛微调基于注解的自动连接。该部分中的示例演示了如何使用@Qualifier 注释和自定义限定符注释在解析自动装配候选时提供细粒度的控制。由于这些示例基于 XML Bean 定义,因此通过使用 XML 中的元素的 qualifier 或 meta 子元素,在候选 Bean 定义上提供了限定符元数据 bean。当依靠类路径扫描来自动检测组件时,可以在候选类上为限定符元数据提供类型级别的注释。下面的三个示例演示了此技术:
与相比@Component,JSR-330 @Named 和 JSR-250 ManagedBean 注释是不可组合的。您应该使用 Spring 的构造型模型来构建自定义组件注释。
JSR-330 标准注释的局限性
当使用标准注释时,您应该知道某些重要功能不可用,如下表所示:
表 6. Spring 组件模型元素与 JSR-330 变体
Spring
javax.inject.*
javax.inject 限制/注释
@Autowired
@Inject
@Inject 没有“必填”属性。可以与 Java 8 一起使用 Optional。
@Component
@Named / @ManagedBean
JSR-330 不提供可组合的模型,仅提供一种识别命名组件的方法。
@Scope(“singleton”)
@Singleton
JSR-330 的默认范围类似于 Spring 的 prototype。但是,为了使其与 Spring 的默认默认值保持一致,默认情况下,在 Spring 容器中声明的 JSR-330 bean 是 a singleton。为了使用之外的范围 singleton,您应该使用 Spring 的@Scope 注释。javax.inject 还提供了 @Scope 批注。不过,此仅用于创建自己的注释。
@Qualifier
@Qualifier / @Named
javax.inject.Qualifier 只是用于构建自定义限定符的元注释。具体的 String 限定词(例如@Qualifier 带有值的 Spring 的限定词)可以通过关联 javax.inject.Named。
@Value
-
没有等效
@Required
-
没有等效
@Lazy
-
没有等效
ObjectFactory
Provider
javax.inject.Provider 是 Spring 的直接替代方法 ObjectFactory,只是 get()方法名称较短。它也可以与 Spring @Autowired 或非注释构造函数和 setter 方法结合使用。
基于 Java 的容器配置
本节介绍如何在 Java 代码中使用注释来配置 Spring 容器。它包括以下主题:
基本概念:@Bean 和 @Configuration
使用实例化 Spring 容器 AnnotationConfigApplicationContext
使用@Bean 注释
使用@Configuration 注释
组成基于 Java 的配置
Bean 定义配置文件
PropertySource 抽象化
运用 @PropertySource
声明中的占位符解析
基本概念:@Bean 和 @Configuration
Spring 的新 Java 配置支持中的主要构件是 @Configuration 注释的类和 @Bean 注释的方法。
@Bean批注用于指示方法实例化,配置和初始化要由 Spring IoC 容器管理的新对象。 对于那些熟悉 Spring 的 <beans/> XML 配置的人来说,@Bean 注释与 <bean/>元素具有相同的作用。 您可以将 @Bean 批注方法与任何 Spring @Component 一起使用。 但是,它们最常与 @Configuration bean 一起使用。
与实例化 ClassPathXmlApplicationContext 时将 Spring XML 文件用作输入的方式几乎相同,您可以在实例化 AnnotationConfigApplicationContext 时将 @Configuration 类用作输入。如下面的示例所示,这允许完全不使用 XML 来使用 Spring 容器:
<web-app> <!-- Configure ContextLoaderListener to use AnnotationConfigWebApplicationContext instead of the default XmlWebApplicationContext --> <context-param> <param-name>contextClass</param-name> <param-value> org.springframework.web.context.support.AnnotationConfigWebApplicationContext </param-value> </context-param>
<!-- Configuration locations must consist of one or more comma- or space-delimited fully-qualified @Configuration classes. Fully-qualified packages may also be specified for component-scanning --> <context-param> <param-name>contextConfigLocation</param-name> <param-value>com.acme.AppConfig</param-value> </context-param>
<!-- Bootstrap the root application context as usual using ContextLoaderListener --> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener>
<!-- Declare a Spring MVC DispatcherServlet as usual --> <servlet> <servlet-name>dispatcher</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <!-- Configure DispatcherServlet to use AnnotationConfigWebApplicationContext instead of the default XmlWebApplicationContext --> <init-param> <param-name>contextClass</param-name> <param-value> org.springframework.web.context.support.AnnotationConfigWebApplicationContext </param-value> </init-param> <!-- Again, config locations must consist of one or more comma- or space-delimited and fully-qualified @Configuration classes --> <init-param> <param-name>contextConfigLocation</param-name> <param-value>com.acme.web.MvcConfig</param-value> </init-param> </servlet>
<!-- map all requests for /app/* to the dispatcher servlet --> <servlet-mapping> <servlet-name>dispatcher</servlet-name> <url-pattern>/app/*</url-pattern> </servlet-mapping> </web-app>
使用 @Bean 注解
@Bean 是方法级别的注解,类似 XML 中的 <bean/> 元素。同时支持提供 <bean/> 的属性,例如:init-method、destroy-method、autowiring。
@Bean @Scope("prototype") public Encryptor encryptor(){ // ... }
}
@Scope 和 scope 代理
Spring 提供了一个通过范围代理来处理范围依赖的便捷方法。使用 XML 配置创建此类代理的最简单方法是元素。使用@Scope 注解配置 Java 中的 bean 提供了与 proxyMode 属性相似的支持。默认是没有代理(ScopedProxyMode.NO),但您可以指定 ScopedProxyMode.TARGET_CLASS 或 ScopedProxyMode.INTERFACES。
如果你使用 Java 将 XML 参考文档(请参阅上述链接)到范围的@Bean 中移植范围限定的代理示例,则它将如下所示 如果你将 XML 参考文档的 scoped 代理示例转化为 Java @Bean,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// an HTTP Session-scoped bean exposed as a proxy @Bean @SessionScope public UserPreferences userPreferences(){ returnnew UserPreferences(); }
@Bean public Service userService(){ UserService service = new SimpleUserService(); // a reference to the proxied userPreferences bean service.setUserPreferences(userPreferences()); return service; }
自定义 Bean 命名
默认情况下,配置类使用@Bean 方法的名称作为结果 bean 的名称。但是,可以使用 name 属性覆盖此功能,如以下示例所示:
1 2 3 4 5 6 7 8
@Configuration publicclassAppConfig{
@Bean(name = "myThing") public Thing thing(){ returnnew Thing(); } }
publicabstractclassCommandManager{ public Object process(Object commandState){ // grab a new instance of the appropriate Command interface Command command = createCommand(); // set the state on the (hopefully brand new) Command instance command.setState(commandState); return command.execute(); }
// okay... but where is the implementation of this method? protectedabstract Command createCommand(); }
@Bean @Scope("prototype") public AsyncCommand asyncCommand(){ AsyncCommand command = new AsyncCommand(); // inject dependencies here as required return command; }
@Bean public CommandManager commandManager(){ // return new anonymous implementation of CommandManager with createCommand() // overridden to return a new prototype Command object returnnew CommandManager() { protected Command createCommand(){ return asyncCommand(); } } }
@Bean public TransferService transferService(){ // navigate 'through' the config class to the @Bean method! returnnew TransferServiceImpl(repositoryConfig.accountRepository()); } }
Spring 的 @Configuration 类支持并非旨在 100% 完全替代 Spring XML。 某些工具(例如 Spring XML 名称空间)仍然是配置容器的理想方法。 在使用 XML 方便或有必要的情况下,您可以选择:使用“以 XML 为中心”的方式实例化容器,比如 ClassPathXmlApplicationContext ,或使用“以 Java 中心”的方式实例化容器,也就是使用 AnnotationConfigApplicationContext 和 @ImportResource 批注来根据需要导入 XML。
以 XML 为中心的 @Configuration 类使用
最好从 XML 引导 Spring 容器并以 ad-hoc 方式包含 @Configuration 类。 例如,在使用 Spring XML 的大型现有代码库中,根据需要创建 @Configuration 类并从现有 XML 文件中将它们包含在内会变得更加容易。 在本节的后面,我们将介绍在这种“以 XML 为中心”的情况下使用 @Configuration 类的选项。
@Bean public AccountRepository accountRepository(){ returnnew JdbcAccountRepository(dataSource); }
@Bean public TransferService transferService(){ returnnew TransferService(accountRepository()); } }
以下示例显示了示例 system-test-config.xml 文件的一部分:
1 2 3 4 5 6 7 8 9 10 11 12 13
<beans> <!-- enable processing of annotations such as @Autowired and @Configuration --> <context:annotation-config/> <context:property-placeholderlocation="classpath:/com/acme/jdbc.properties"/>
<beans> <!-- picks up and registers AppConfig as a bean definition --> <context:component-scanbase-package="com.acme"/> <context:property-placeholderlocation="classpath:/com/acme/jdbc.properties"/>
<!-- this MessageSource is being used in a web application --> <beanid="messageSource"class="org.springframework.context.support.ResourceBundleMessageSource"> <propertyname="basename"value="exceptions"/> </bean>
<!-- lets inject the above MessageSource into this POJO --> <beanid="example"class="com.something.Example"> <propertyname="messages"ref="messageSource"/> </bean>
@EventListener public ListUpdateEvent handleBlackListEvent(BlackListEvent event){ // notify appropriate parties via notificationAddress and // then publish a ListUpdateEvent... }
可以将 Spring ApplicationContext 部署为 RAR 文件,并将上下文及其所有必需的 bean 类和库 JAR 封装在 Java EE RAR 部署单元中。这等效于引导独立的 ApplicationContext(仅托管在 Java EE 环境中)能够访问 Java EE 服务器功能。 RAR 部署是部署无头 WAR 文件的方案的一种更自然的选择——实际上,这种 WAR 文件没有任何 HTTP 入口点,仅用于在 Java EE 环境中引导 Spring ApplicationContext。
对于将 Spring ApplicationContext 作为 Java EE RAR 文件的简单部署:
将所有应用程序类打包到 RAR 文件(这是具有不同文件扩展名的标准 JAR 文件)中。将所有必需的库 JAR 添加到 RAR 归档文件的根目录中。添加一个 META-INF/ra.xml 部署描述符(如 javadoc 中的 SpringContextResourceAdapter 所示)和相应的 Spring XML bean 定义文件(通常为 META-INF/applicationContext.xml)。
BeanFactory API 为 Spring 的 IoC 功能提供了基础。它的特定合同主要用于与 Spring 的其他部分以及相关的第三方框架集成,并且它的 DefaultListableBeanFactory 实现是更高级别的 GenericApplicationContext 容器中的关键委托。
DefaultListableBeanFactory factory = new DefaultListableBeanFactory(); XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory); reader.loadBeanDefinitions(new FileSystemResource("beans.xml"));
// bring in some property values from a Properties file PropertySourcesPlaceholderConfigurer cfg = new PropertySourcesPlaceholderConfigurer(); cfg.setLocation(new FileSystemResource("jdbc.properties"));
// now actually do the replacement cfg.postProcessBeanFactory(factory);
AnnotationConfigApplicationContext 已注册了所有常见的注释后处理器,并且可以通过配置注释(例如 @EnableTransactionManagement)在幕后引入其他处理器。 在 Spring 基于注释的配置模型的抽象级别上,bean 后处理器的概念仅是内部容器详细信息。
]]> 技术 阅读 Spring Java <![CDATA[Spring进阶 - IoC容器(1)]]>https://HaleLu.github.io/2020/02/spring-1/本系列基于 Spring Framework 文档深入探究 Spring 的使用姿势及原理。
一些简单概念略过不讲,希望阅读这篇文章的你对 Spring 有一定了解。
本文讲第一部分——IoC 容器、bean 概述、依赖注入和 bean 的作用域。
简介
Spring Framework 的 IoC 容器主要在 org.springframework.beans 和 org.springframework.context 这两个包里,BeanFactory 接口提供了更高级的注册机制能够管理任意类型的对象。 ApplicationContext 接口继承了 BeanFactory 接口,并添加了更易与 Spring AOP 集成的特性、消息资源管理(用于国际化)、事件发布、应用层特定上下文(例如用于 web 应用的 WebApplicationContext)。简而言之,BeanFactory 提供了注册框架和基础功能,ApplicationContext 增加了更多企业级应用的特定功能。本章重点讲 ApplicationContext,关于 BeanFactory 详见下文。
容器概论
ApplicationContext 接口表示 Spring 的 IoC 容器,它负责实例化(instantiate)、配置和组装 beans。ApplicationContext 通过从 XML、注解或是代码得知哪些类需要被加载、以何种方式加载、依赖关系是什么。
Spring 提供了一些 ApplicationContext 的实现,常见的例如 ClassPathXmlApplicationContext 和 FileSystemXmlApplicationContext,都是通过 XML 配置来实现的。大多数场景下,用户代码并不需要自己实例化出一个 Spring IoC 容器,可以通过一个简单的 web.xml 便可实现。
下图简要展示了 Spring IoC 容器的工作原理,你的 POJOs 结合配置项元数据,这样,ApplicationContext 创建并初始化后,你就拥有了一个配置完全且可运行的系统/应用。
配置项元数据(Configuration Metadata)
上文说了,Spring IoC 容器使用配置项元数据的形式配置,支持传统的 XML 格式,从 Spring 2.5 开始支持基于注解的配置项元数据,从 3.0 开始,Spring JavaConfig 提供的很多特性使你可以通过一些类来定义 beans,包括 @Configuration、 @Bean、@Import 以及 @DependsOn 等注解。
Spring 配置项包含一个或多个容器管理的 bean 定义(definition)。在 XML 中使用<beans/>中的<bean/>标签,代码方式则在@Configuration注解的类中使用@Bean注解的方法。通常我们用其定义服务层对象、DAOs、展示对象、基础设置对象(例如一些框架工厂类)等等。通常在容器中不注册细粒度的域对象,因为这通常是 DAOs 的责任,应当又业务逻辑创建和加载这些对象。不过,你可以使用 Spring 的 AspectJ 集成来注册在 IoC 容器控制之外创建的对象。详见下文。
<beanid="petStore"class="org.springframework.samples.jpetstore.services.PetStoreServiceImpl"> <propertyname="accountDao"ref="accountDao"/> <propertyname="itemDao"ref="itemDao"/> <!-- additional collaborators and configuration for this bean go here --> </bean>
<!-- more bean definitions for services go here -->
<beanid="accountDao" class="org.springframework.samples.jpetstore.dao.jpa.JpaAccountDao"> <!-- additional collaborators and configuration for this bean go here --> </bean>
<beanid="itemDao"class="org.springframework.samples.jpetstore.dao.jpa.JpaItemDao"> <!-- additional collaborators and configuration for this bean go here --> </bean>
<!-- more bean definitions for data access objects go here -->
GenericApplicationContext context = new GenericApplicationContext(); new XmlBeanDefinitionReader(context).loadBeanDefinitions("services.xml", "daos.xml"); context.refresh();
<!-- the factory bean, which contains a method called createInstance() --> <beanid="serviceLocator"class="examples.DefaultServiceLocator"> <!-- inject any dependencies required by this locator bean --> </bean>
<!-- the bean to be created via the factory bean --> <beanid="clientService" factory-bean="serviceLocator" factory-method="createClientServiceInstance"/>
1 2 3 4 5 6 7 8
publicclassDefaultServiceLocator{
privatestatic ClientService clientService = new ClientServiceImpl();
public ClientService createClientServiceInstance(){ return clientService; } }
当然,一个工厂类可以有多个工厂方法。
注:在 Spring 文档中,“工厂 bean”是指在 Spring 容器中配置并通过实例或静态工厂方法创建对象的 bean。 相比之下,FactoryBean(注意大小写)是指特定于 Spring 的 FactoryBean。
依赖
典型的企业应用程序不会只包含单个对象(或 Spring 说法中的 bean)。即使是最简单的应用程序也有一些对象可以协同工作,以呈现最终用户所看到的连贯应用程序。这节讲如何定义多个独立的 bean 定义,以及对象协作实现目标的完全实现的应用程序。
基于构造函数的 DI 由容器调用具有多个参数的构造函数来完成,每个参数表示一个依赖项。这跟调用具有相同参数的静态工厂方法来构造 bean 是等效的,下面的解释同样适用于静态工厂方法。举个简单的 POJO 的例子:
1 2 3 4 5 6 7 8 9 10 11 12
publicclassSimpleMovieLister{
// the SimpleMovieLister has a dependency on a MovieFinder private MovieFinder movieFinder;
// a constructor so that the Spring container can inject a MovieFinder publicSimpleMovieLister(MovieFinder movieFinder){ this.movieFinder = movieFinder; }
// business logic that actually uses the injected MovieFinder is omitted... }
// the SimpleMovieLister has a dependency on the MovieFinder private MovieFinder movieFinder;
// a setter method so that the Spring container can inject a MovieFinder publicvoidsetMovieFinder(MovieFinder movieFinder){ this.movieFinder = movieFinder; }
// business logic that actually uses the injected MovieFinder is omitted... }
<!-- typed as a java.util.Properties --> <propertyname="properties"> <value> jdbc.driver.className=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost:3306/mydb </value> </property> </bean>
Spring 容器通过使用 JavaBeans 机制将 <value/> 元素内的文本转换为 java.util.Properties 实例 PropertyEditor。这是一个很好的快捷方式,也是 Spring 团队支持 <value/> 在 value 属性样式上使用嵌套元素的少数几个地方之一。
<!-- in the parent context --> <beanid="accountService"class="com.something.SimpleAccountService"> <!-- insert dependencies as required as here --> </bean>
1 2 3 4 5 6 7 8
<!-- in the child (descendant) context --> <bean id="accountService" <!-- bean name is the same as the parent bean --> class="org.springframework.aop.framework.ProxyFactoryBean"> <propertyname="target"> <refparent="accountService"/><!-- notice how we refer to the parent bean --> </property> <!-- insert other configuration and dependencies as required here --> </bean>
<beanid="outer"class="..."> <!-- instead of using a reference to a target bean, simply define the target bean inline --> <propertyname="target"> <beanclass="com.example.Person"><!-- this is the inner bean --> <propertyname="name"value="Fiona Apple"/> <propertyname="age"value="25"/> </bean> </property> </bean>
<beanid="moreComplexObject"class="example.ComplexObject"> <!-- results in a setAdminEmails(java.util.Properties) call --> <propertyname="adminEmails"> <props> <propkey="administrator">administrator@example.org</prop> <propkey="support">support@example.org</prop> <propkey="development">development@example.org</prop> </props> </property> <!-- results in a setSomeList(java.util.List) call --> <propertyname="someList"> <list> <value>a list element followed by a reference</value> <refbean="myDataSource" /> </list> </property> <!-- results in a setSomeMap(java.util.Map) call --> <propertyname="someMap"> <map> <entrykey="an entry"value="just some string"/> <entrykey ="a ref"value-ref="myDataSource"/> </map> </property> <!-- results in a setSomeSet(java.util.Set) call --> <propertyname="someSet"> <set> <value>just some string</value> <refbean="myDataSource" /> </set> </property> </bean>
map 的键和值、set 的值也可以是以下类型:
1
bean | ref | idref | list | set | map | props | value | null
合并集合
Spring 容器还支持合并集合。你可以定义父<list/>,<map/>,<set/>或<props/>元素,然后定义子<list/>,<map/>,<set/>或<props/>元素继承和覆盖父集合中的值。 也就是说,子集合的值是合并父集合和子集合的元素的结果,相同时子集合的元素覆盖父集合中指定的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
<beans> <beanid="parent"abstract="true"class="example.ComplexObject"> <propertyname="adminEmails"> <props> <propkey="administrator">administrator@example.com</prop> <propkey="support">support@example.com</prop> </props> </property> </bean> <beanid="child"parent="parent"> <propertyname="adminEmails"> <!-- the merge is specified on the child collection definition --> <propsmerge="true"> <propkey="sales">sales@example.com</prop> <propkey="support">support@example.co.uk</prop> </props> </property> </bean> <beans>
public Object process(Map commandState){ // grab a new instance of the appropriate Command Command command = createCommand(); // set the state on the (hopefully brand new) Command instance command.setState(commandState); return command.execute(); }
protected Command createCommand(){ // notice the Spring API dependency! returnthis.applicationContext.getBean("command", Command.class); }
public Object process(Object commandState){ // grab a new instance of the appropriate Command interface Command command = createCommand(); // set the state on the (hopefully brand new) Command instance command.setState(commandState); return command.execute(); }
// okay... but where is the implementation of this method? protectedabstract Command createCommand(); }
<!-- a stateful bean deployed as a prototype (non-singleton) --> <beanid="myCommand"class="fiona.apple.AsyncCommand"scope="prototype"> <!-- inject dependencies here as required --> </bean>
/** * meant to be used to override the existing computeValue(String) * implementation in MyValueCalculator */ publicclassReplacementComputeValueimplementsMethodReplacer{
public Object reimplement(Object o, Method m, Object[] args)throws Throwable { // get the input value, work with it, and return a computed result String input = (String) args[0]; ... return ...; } }
仅当使用 Web 感知的 Spring ApplicationContext 实现(例如 XmlWebApplicationContext)时,Request、Session、Application 和 websocket 作用域才可用。如果将这些作用域与常规的 Spring IoC 容器(例如 ClassPathXmlApplicationContext)一起使用,则会引发由于未知 bean 作用域的 IllegalStateException。
初始 Web 配置
要在请求,会话,应用程序和 websocket 级别(统称 Web 作用域)支持 bean 的作用域,在定义 bean 之前需要做一些初始配置。(单例和原型这两种标准范围不需要此初始设置)
如何初始设置取决于具体的 Servlet 环境。
如果在 Spring Web MVC 中访问 scoped bean,实际上是在 Spring DispatcherServlet 处理的请求中,则无需进行特殊设置。 DispatcherServlet 已经公开了所有相关状态。
#ifndef HAVE_MALLOC_SIZE size_t zmalloc_size(void *ptr) { void *realptr = (char*)ptr-PREFIX_SIZE; size_t size = *((size_t*)realptr); /* Assume at least that all the allocations are padded at sizeof(long) by * the underlying allocator. */ if (size&(sizeof(long)-1)) size += sizeof(long)-(size&(sizeof(long)-1)); return size+PREFIX_SIZE; } #endif
size_t zmalloc_get_rss(void) { int page = sysconf(_SC_PAGESIZE); size_t rss; char buf[4096]; char filename[256]; int fd, count; char *p, *x;
snprintf(filename,256,"/proc/%d/stat",getpid()); if ((fd = open(filename,O_RDONLY)) == -1) return0; if (read(fd,buf,4096) <= 0) { close(fd); return0; } close(fd);
p = buf; count = 23; /* RSS is the 24th field in /proc/<pid>/stat */ while(p && count--) { p = strchr(p,' '); if (p) p++; } if (!p) return0; x = strchr(p,' '); if (!x) return0; *x = '\0';
return t_info.resident_size; } #else //使用used_memory值,并不是准确的RSS,会使得碎片率固定为1 size_t zmalloc_get_rss(void) { /* If we can't get the RSS in an OS-specific way for this system just * return the memory usage we estimated in zmalloc().. * * Fragmentation will appear to be always 1 (no fragmentation) * of course... */ return zmalloc_used_memory(); } #endif
/* Get the sum of the specified field (converted form kb to bytes) in * /proc/self/smaps. The field must be specified with trailing ":" as it * apperas in the smaps output. * * If a pid is specified, the information is extracted for such a pid, * otherwise if pid is -1 the information is reported is about the * current process. * * Example: zmalloc_get_smap_bytes_by_field("Rss:",-1); */ #if defined(HAVE_PROC_SMAPS) size_t zmalloc_get_smap_bytes_by_field(char *field, long pid) { char line[1024]; size_t bytes = 0; int flen = strlen(field); FILE *fp;
using System; using System.Threading; using System.Threading.Tasks;
namespaceConsoleApp { classProgram { staticvoidMain(string[] args) { var manualResetEvent = new ManualResetEvent(false); var task1 = new Task(() => { Console.WriteLine("task1 : Before WaitOne()"); manualResetEvent.WaitOne(); Console.WriteLine("task1 : After WaitOne()"); }); var task2 = new Task(() => { Console.WriteLine("task2 : Before Set()"); manualResetEvent.Set(); Console.WriteLine("task2 : After Set()"); });
task1.Start(); Thread.Sleep(1000); task2.Start();
Task.WaitAll(task1, task2); } } }
运行结果如下:
1 2 3 4 5
task1 : Before WaitOne() task2 : Before Set() task2 : After Set() task1 : After WaitOne() 请按任意键继续. . .
using System; using System.Threading; using System.Threading.Tasks;
namespaceConsoleApp { classProgram { staticvoidMain(string[] args) { var manualResetEvent = new ManualResetEvent(false); var task1 = new Task(() => { Console.WriteLine("task1 : Before WaitOne()"); manualResetEvent.WaitOne(); Console.WriteLine("task1 : After WaitOne()"); });
var task2 = new Task(() => { Console.WriteLine("task2 : Before WaitOne()"); manualResetEvent.WaitOne(); Console.WriteLine("task2 : After WaitOne()"); });
var task3 = new Task(() => { Console.WriteLine("task3 : Before Set()"); manualResetEvent.Set(); Console.WriteLine("task3 : After Set()"); });
task2 : Before WaitOne() task1 : Before WaitOne() task3 : Before Set() task3 : After Set() task1 : After WaitOne() task2 : After WaitOne() 请按任意键继续. . .
using System; using System.Threading; using System.Threading.Tasks;
namespaceConsoleApp { classProgram { staticvoidMain(string[] args) { var autoResetEvent = new AutoResetEvent(false); var task1 = new Task(() => { Console.WriteLine("task1 : Before WaitOne()"); autoResetEvent.WaitOne(); Console.WriteLine("task1 : After WaitOne()"); });
var task2 = new Task(() => { Console.WriteLine("task2 : Before WaitOne()"); autoResetEvent.WaitOne(); Console.WriteLine("task2 : After WaitOne()"); });
var task3 = new Task(() => { Console.WriteLine("task3 : Before Set()"); autoResetEvent.Set(); Console.WriteLine("task3 : After Set()"); });
为了增强可读性,控制器和模型可以添加 XML 文档注释,并在注册 Swashbuckle 时将这些注释包含进 Swagger JSON:
打开项目的“属性”选项,选择“生成”标签页并勾上“ XML 文档文件”。然后当你生成项目时可以它会自动生成一个包含所有 XML 注释的文件。
此时如果某个类或方法没有使用 XML 注释,那么会产生一个生成警告。如果想要去掉这个警告,在此页的“禁止显示警告”选项中添加警告码“1591”即可。
在注册 Swashbuckle 时引用 XML 注释文件来生成 Swagger JSON:
1 2 3 4 5 6 7 8 9 10 11 12 13
services.AddSwaggerGen(c => { c.SwaggerDoc("v1", new Info { Title = "My API - V1", Version = "v1" } );
var filePath = Path.Combine(PlatformServices.Default.Application.ApplicationBasePath, "MyApi.xml"); c.IncludeXmlComments(filePath); }
方法注释应当有 summary、 remarks 和 response 标签。
1 2 3 4 5 6 7 8 9 10 11 12
///<summary> /// Retrieves a specific product by unique id ///</summary> ///<remarks>Awesomeness!</remarks> ///<response code="200">Product created</response> ///<response code="400">Product has missing/invalid values</response> ///<response code="500">Oops! Can't create your product right now</response> [HttpGet("{id}")] [ProducesResponseType(typeof(Product), 200)] [ProducesResponseType(typeof(IDictionary<string, string>), 400)] [ProducesResponseType(typeof(void), 500)] public Product GetById(int id)
c.SwaggerDoc("v1", new Info { Title = "My API - V1", Version = "v1", Description = "A sample API to demo Swashbuckle", TermsOfService = "Knock yourself out", Contact = new Contact { Name = "Joe Developer", Email = "joe.developer@tempuri.org" }, License = new License { Name = "Apache 2.0", Url = "http://www.apache.org/licenses/LICENSE-2.0.html" } } )
[ CA_root ] new_certs_dir = $dir/newcerts # default place for new certs.
private_key = $dir/private/ca.key # The private key certificate = $dir/ca.crt # The CA certificate
database = $dir/index.txt # database index file. serial = $dir/serial # The current serial number crlnumber = $dir/crlserial # the current crl number RANDFILE = $dir/private/.rand # private random number file
preserve = no name_opt = ca_default cert_opt = ca_default
[ req_distinguished_root ] countryName = Country Name (2 letter code) countryName_min = 2 countryName_max = 2
stateOrProvinceName = State or Province Name (full name)
localityName = Locality Name (eg, city)
organizationName = Organization Name (eg, company)
organizationalUnitName = Organizational Unit Name (eg, section)
commonName = Common Name (e.g. server FQDN or YOUR name) commonName_max = 64
countryName_default = CN stateOrProvinceName_default = Your Province organizationName_default = Your Company Name organizationalUnitName_default = Secure Digital Certificate Signing commonName_default = The Root CA of Your Private Certifications
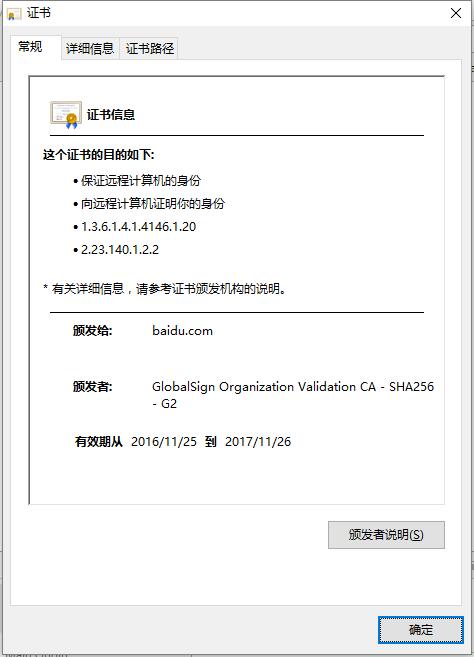
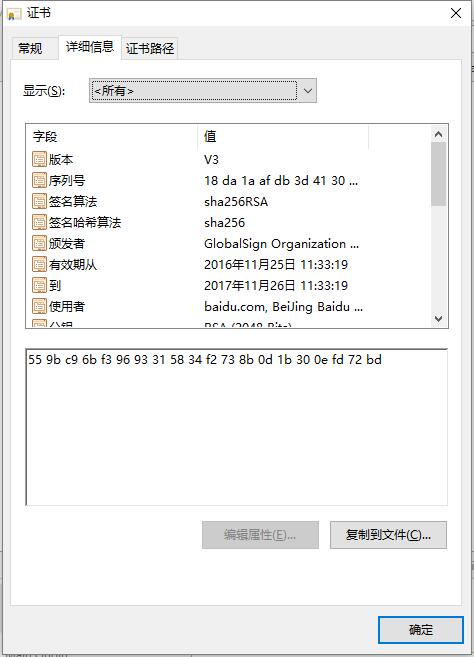
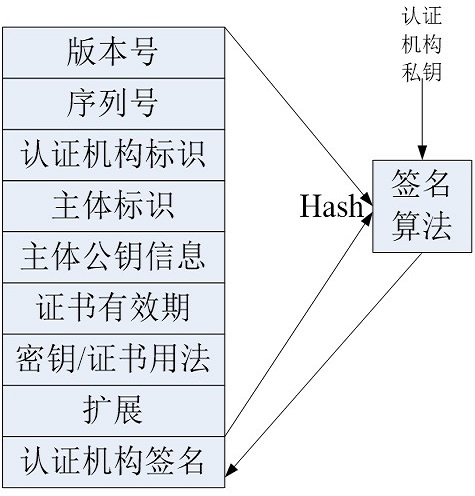
所以,通常我们看到的证书都是一条证书链。通常 根CA 不签发末端的客户证书,只负责签发 CA 证书,而 CA 根据他们证书中被授予的权限,有些可以签发下级CA有些只可以签发客户证书。 每张证书都会有过期时间和一个证书撤销列表(CRL)的URL。如果一张证书过期或被写进了CRL,那么证书就会作废(这往往是由私钥泄露导致的)。
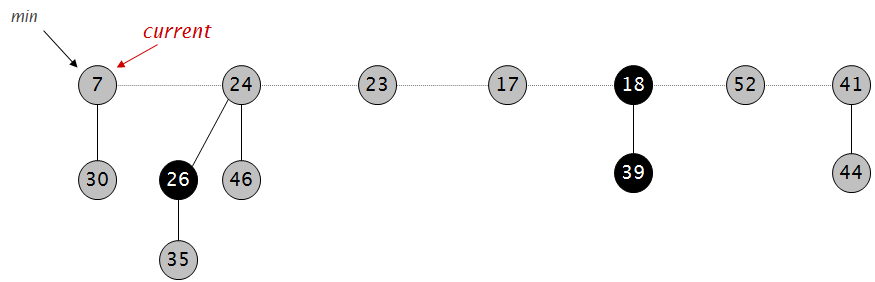
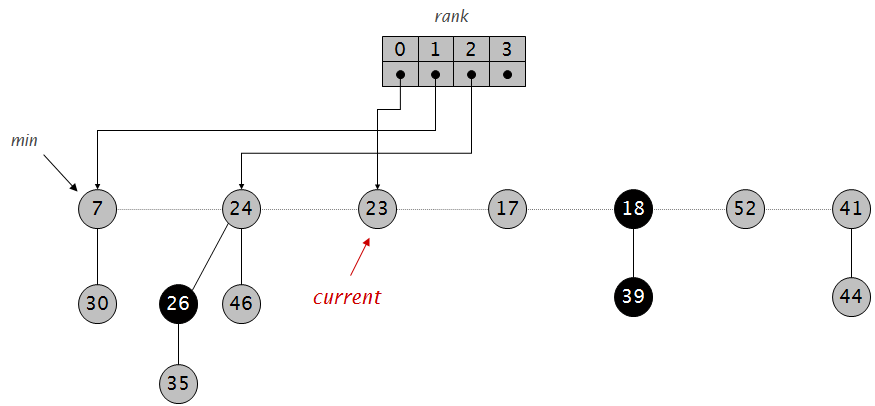
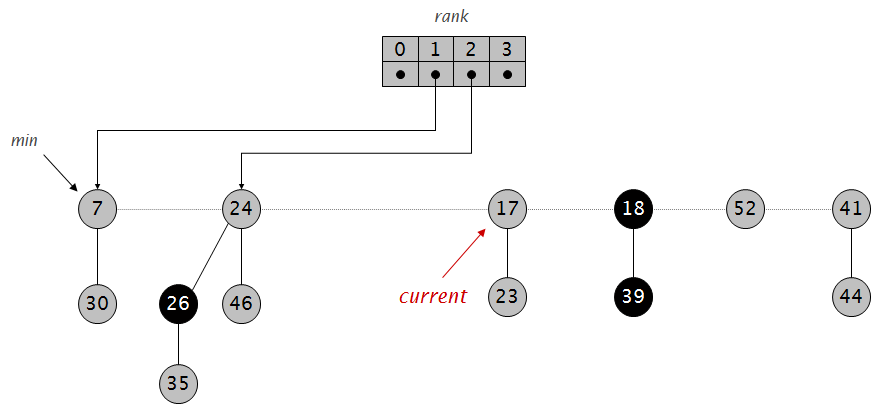
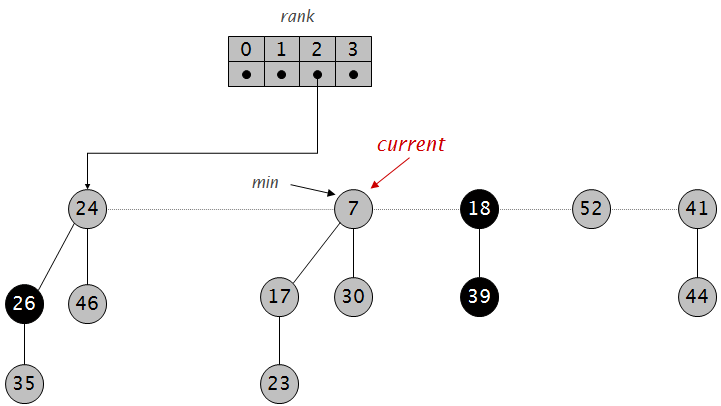
int first[MAXN*20], last[MAXN*2], next[MAXN*2], num; int first1[MAXN*20], last1[MAXN*2], next1[MAXN*2], num1; int first2[MAXN*20], last2[MAXN*2], next2[MAXN*2], num2; int first3[MAXN*20], last3[MAXN*2], next3[MAXN*2], num3; int first4[MAXN*20], last4[MAXN*2], next4[MAXN*2], num4; int d[MAXN]; int w[MAXN]; int ans[MAXN]; int up[MAXN*2]; int down[MAXN*2]; int f[MAXN][25];
intlca(int x, int y) { if (d[x] < d[y]) { swap(x, y); } for (int i=20; i>=0; i--) { if (d[f[x][i]] >= d[y]) { x = f[x][i]; } } if (d[x] != d[y]) x = f[x][0]; for (int i=20; i>=0; i--) { if (f[x][i] != f[y][i]) { x = f[x][i]; y = f[y][i]; } } return (x != y) ? f[x][0] : x; }
voiddfs(int v) { int x = up[d[v]+w[v]]; int y = down[d[v]-w[v]+MAXN]; for (int i=first1[v]; i; i=next1[i]) { up[last1[i]]++; } for (int i=first2[v]; i; i=next2[i]) { down[last2[i]+MAXN]++; } for (int i=first[v]; i; i=next[i]) { if (last[i] != f[v][0]) { dfs(last[i]); } } ans[v] = up[d[v]+w[v]] + down[d[v]-w[v]+MAXN]-x-y; for (int i=first3[v]; i; i=next3[i]) { up[last3[i]]--; if (last3[i] == d[v]+w[v]) ans[v]--; } for (int i=first4[v]; i; i=next4[i]) { down[last4[i]+MAXN]--; } }
voidcalc_deep(int v, int fa) { d[v] = d[fa]+1; f[v][0] = fa; for (int i = first[v]; i; i=next[i]) { if (last[i] != fa) { calc_deep(last[i], v); } } }
voidadd(int u, int v) { last[++num] = v; next[num] = first[u]; first[u] = num; }
voidadd_up(int u, int v) { last1[++num1] = v; next1[num1] = first1[u]; first1[u] = num1; }
voidadd_down(int u, int v) { last2[++num2] = v; next2[num2] = first2[u]; first2[u] = num2; }
voidadd_top_up(int u, int v) { last3[++num3] = v; next3[num3] = first3[u]; first3[u] = num3; }
voidadd_top_down(int u, int v) { last4[++num4] = v; next4[num4] = first4[u]; first4[u] = num4; }
intmain() { int n, m; scanf("%d%d", &n, &m); for (int i=0; i<n-1; i++) { int u, v; scanf("%d%d", &u, &v); add(u, v); add(v, u); } calc_deep(1, 0); for (int j=1; j<=20; j++) { for (int i=1; i<=n ;i++) { f[i][j] = f[f[i][j-1]][j-1]; } } for (int i=1; i<=n; i++) { scanf("%d", &w[i]); } for (int i=1; i<=m; i++) { int s, t; scanf("%d%d", &s, &t); int top = lca(s, t); int len = d[s]+d[t]-d[top]-d[top]; int diff = d[t] - len; add_up(s, d[s]); add_down(t, diff); add_top_up(top, d[s]); add_top_down(top, diff); }
]]> 算法 算法 ACM <![CDATA[在 .NET Core 项目中添加 WCF Service]]>https://HaleLu.github.io/2016/07/How-to-Add-Net-Service-in-NET-Core/What is Web Service?
微软的 ASP.NET Web Service 是一套基于XML扩展标记语言,使用Soap简单对象访问协议实现的网络数据交互服务。它使用 WSDL 来描述服务相关的接口。 ASP.NET Web Service 必须依赖于 IIS,是一种无状态的通讯协议。
Why WCF?
从某种程度上来说,Web Service 是 WCF(Windows Communication Foundation)的子集,它支持 Web Service 的所有标准。当然它不仅仅支持 Web Service,它是微软为整合.NET平台下所有的和分布式系统有关的技术而创建的统一框架。 WCF 相对 Web Service 的优势很多,不在此一一举例。 在 .NET Core 的正式版中,大概是由于跨平台的需要,微软抛弃了 Web Service,所以我们只能用 WCF 来添加网络服务。
How to?
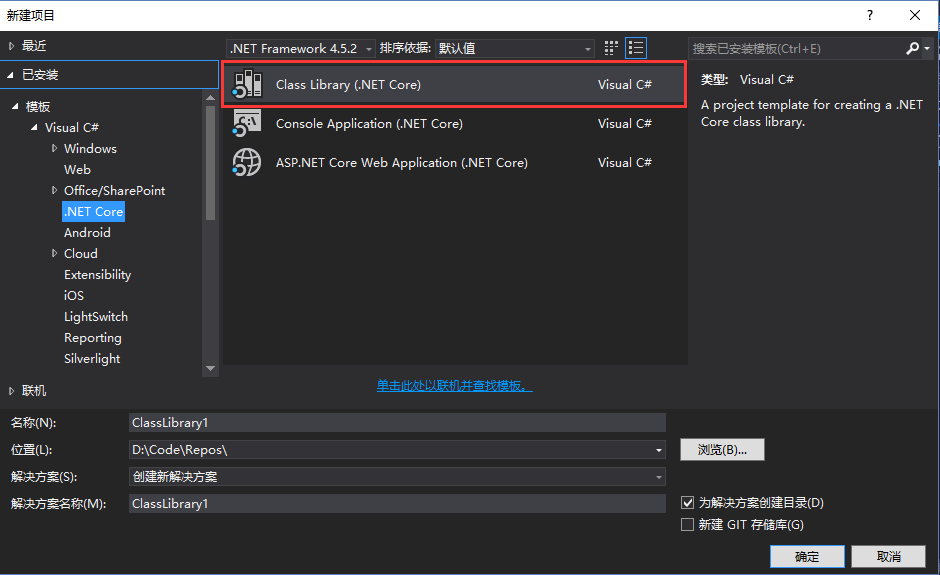
首先可以在这里下载安装 Visual Studio WCF Connected Service 的扩展。 其次,创建一个 .NET Core 项目(以类库项目为例)。 在项目中添加 WCF 服务: 添加对应的 Webservice.asmx,修改相关参数(其实只要改名字就好),一路 next 然后 Finish: 对应的 Web Service 就添加成功了~
Finally, .NET Core will be “pay-for-play” and performant. One goal of the .NET Core effort is to make the cost of abstraction clear to developers, by implementing a pay-for-play model that makes obvious the costs that come from employing a higher-level abstraction to solve a problem. Abstractions don’t come for free, and that truth should never be hidden from developers. Additionally, .NET Core will favor performance with a standard library that minimizes allocations and the overall memory footprint of your system.
.NET CLI
.NET Core 提供了 .NET CLI(Command Line Interface),可以通过命令行来完成程序的编译,相关命令如下:
模块名:alu 说明:算逻部件 输入接口:op(4位,运算符编码), a, b(32位,运算数) 输出接口:zero(结果是否为0), dout(32位,运算结果) op的说明: 0010: dout = a + b 0110: dout = a - b 0001: dout = a | b 0000: dout = a & b 0111: dout = a < b ? 1 : 0
voiddeal(int r) { if (2*r <= n) deal(2*r); if (flag) return; x--; if (x==0) { flag = true; ans = r; return; } if (2*r+1 <= n) deal(2*r+1); if (flag) return; }
intmain() { int T; scanf("%d", &T); for (int id=1;id<=T;id++) { scanf("%d%d", &n, &x); flag = false; deal(1); printf("Case #%d: %d\n", id, ans); } }
voiddeal() { memset(v,false,sizeof(v)); ans=0; int nn=k; for (int i=1;i<n;i++) nn *= k; for (int i=0;i<nn;i++) { if (!v[i]) { ans++; int ii=i; v[i] = true; for (int j=1;j<n;j++) { ii = (ii%k)*(nn/k)+ii/k; v[ii] = true; } } } }
voiddeal(double l, double r) { double m = (l+r)/2; double s1=0; double s2=0; for (int i=1;i<=n;i++) { if (a[i]>m) s1 += a[i] - m; else s2 += m - a[i]; } s1 *= (1-k); if (abs(s1-s2) < 1e-7) { ans = m; flag = false; } elseif (s1 > s2) deal(m,r); else deal(l,m); }
intmain() { int T; scanf("%d", &T); for (int id=1;id<=T;id++) { scanf("%d%lf", &n, &k); for (int i=1;i<=n;i++) { scanf("%d",&a[i]); } flag = true; deal(1, 10000); printf("Case #%d: %lf\n", id, ans); } }
G
猜数游戏。 B 想一个数(1 到 n),A 猜对了可以从 B 那里赢1刀,如果 A 猜了 x 而 B 想的是 x+1 则 A 要支付1刀给 B 。 B 使用随机数发生器,同时 B 能决定每个数字的分布。而 A 知道 B 的决定,所以 A 会挑选一个获利期望最大的选择。 B 现在要将 A 的获利最小化,问最小化的 A 的获利期望是多少。
var c = new Class { Number = "001" }; c.Students.Add(new Student() { Name = "Hale Lu" }); c.Students.Add(new Student() { Name = "PM Extra" }); dbContext.Classes.Add(c); dbContext.SaveChanges();
... protectedoverridevoidOnConfiguring(DbContextOptionsBuilder optionsBuilder) { // Visual Studio 2015 | Use the LocalDb 12 instance created by Visual Studio optionsBuilder.UseSqlServer(@"Server=(localdb)\mssqllocaldb;Database=EFGetStarted.ConsoleAppFortest.DbForTest;Trusted_Connection=True"); } ... }